前言
vLLM 是一個 LLM 的推論框架,將 LLM 部署於產品上的話滿多人會選擇 vLLM 框架,其他也有像 Huggingface 的 TGI(text generative inference)、TensorRT-LLM等; 小弟認為 vLLM 的最大優勢是支援 batch inference 而且非常的快速,目前工作上也是用 vLLM 來進行 LLM 的部署,本篇主要會說明 vLLM 的運作原理,用來做 LLM 加速的技術其實還有很多,看之後有沒有機會寫成一篇介紹,像是 Flash attention、Quantization等方法。這篇不會講太多論文的內容,但如果想暸解更深的細節可以去讀一下這篇paper,連結放在最後的參考資料中,這篇主要會快速帶一下觀念、原理以及如何使用 vLLM 這個套件來推論
LLM 推論的過程
在介紹 vLLM 前先快速說明一下 LLM 生成 tokens的過程
LLM 生成的概念,以 GPT-2 為例,會生成新的tokens之後,再用舊的 Input + “第一個新生成的token” 當作 Input 餵給 GPT-2 後再請他產生後面的token,如下面的 GIF 動畫,一開始 Input 只有 ”recite the first law $” 餵給GPT-2,然後 GPT-2生成了新的 token “A”,這個 “A” 會再 append 到輸入的後面,變成 ”recite the first law $ A”作為新的 Input 餵給 GPT-2,一直讓 GPT-2 生成停止為止:

但如上面的做法會有一個問題,如果不斷的 append 新的 token 到 Input 上,Input 會越來越長,每個 ”token” 都需要過一個 Wk 與 Wv 來轉成 key 與 value 向量,然後與新的詞(query 向量)去做attention(注意力機制的部分我這邊就不細講了XD),那每次預測下一個token時都需要重複產生前面的 key 與 value 向量,這件事是滿浪費時間的,因此才會有 KV cache 的出現。
所以 KV cache 就是將以計算過 token 的 key value 向量先存起來,在做新的一輪預測時就不用再重複計算前面的 key 與 value 的向量; 這篇作者有稍微比較過時間,時間上是節省了不少,如下面的 GIF,紫色的部分就是存在 KV cache 裡的。
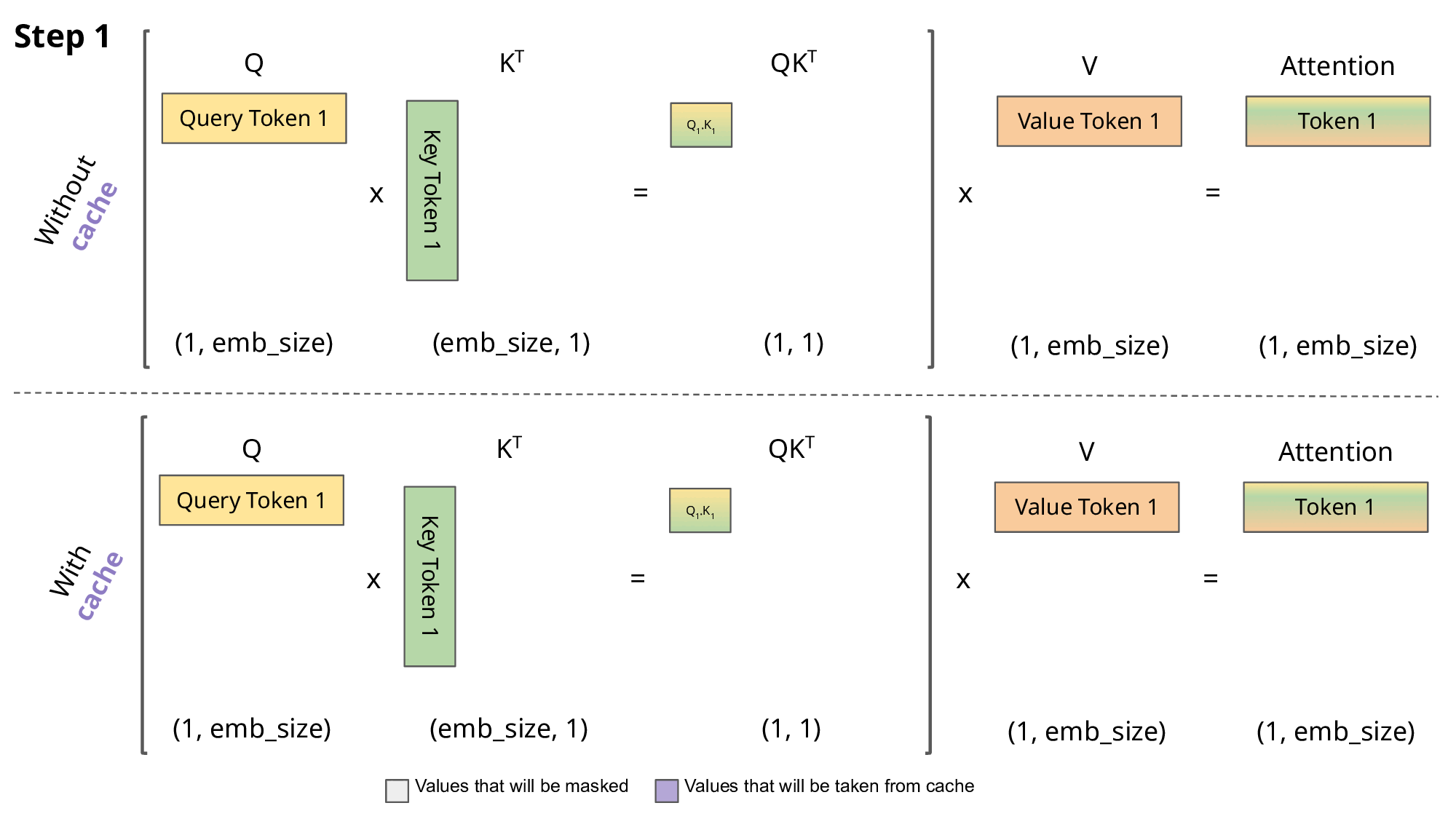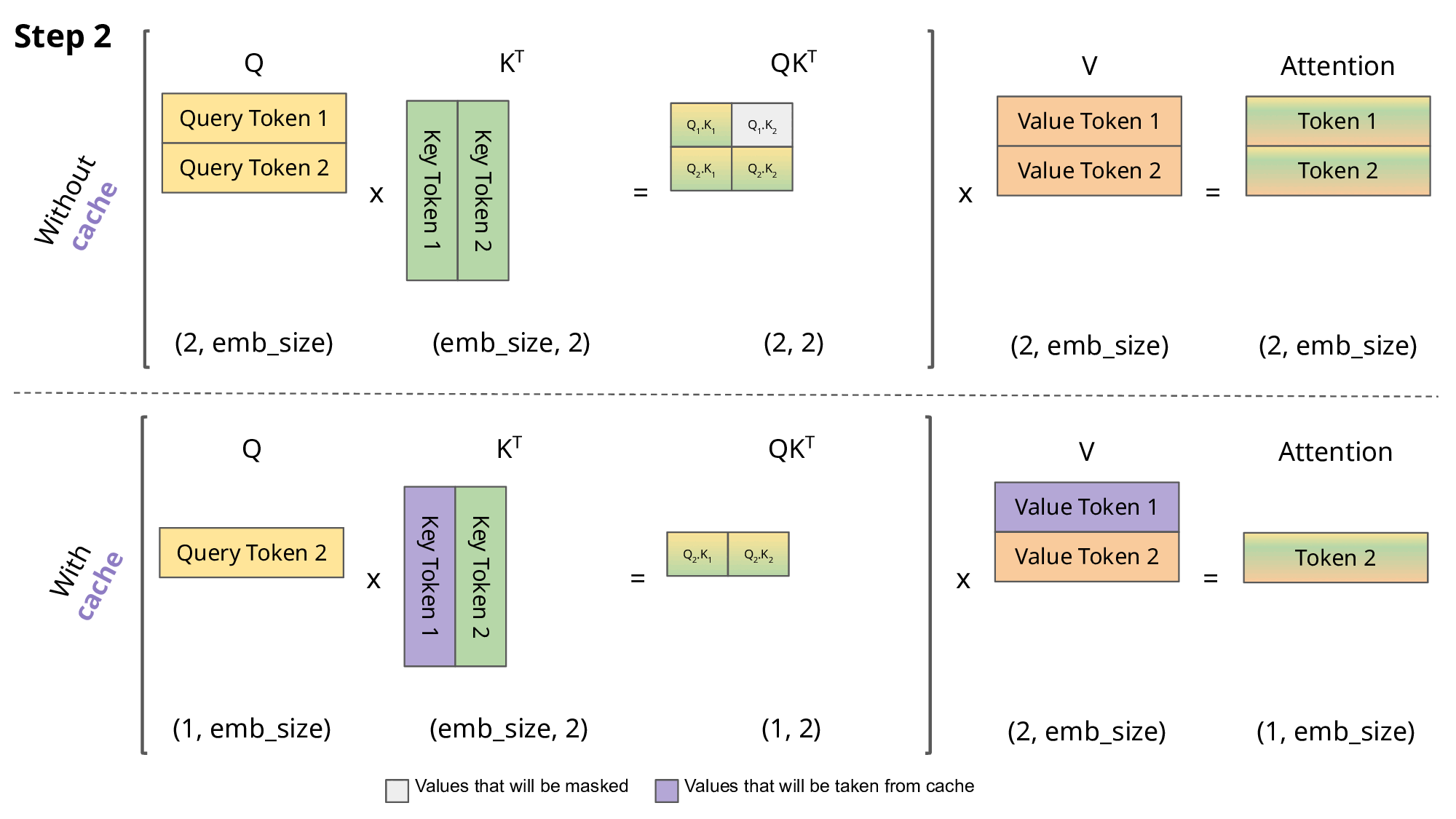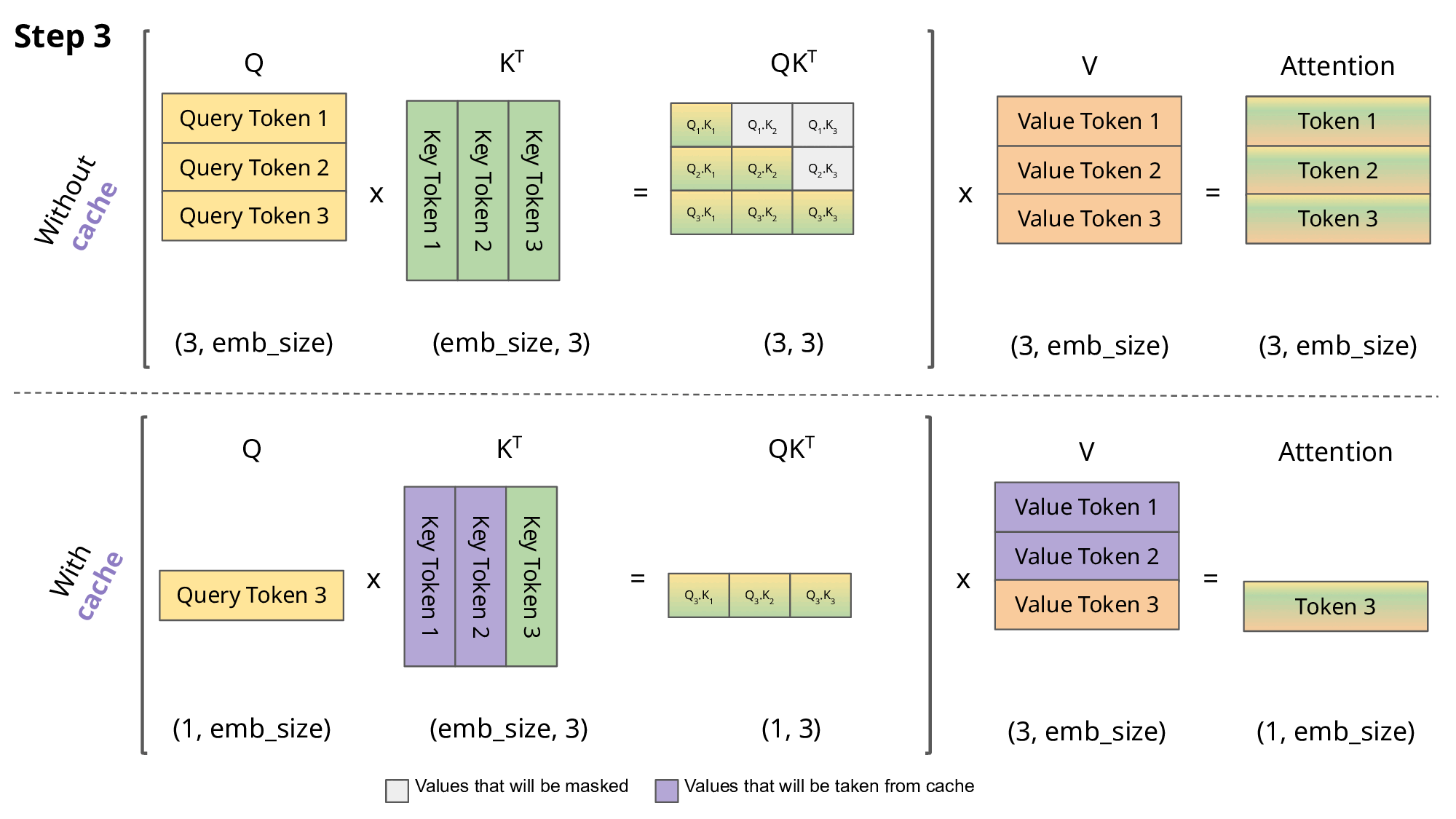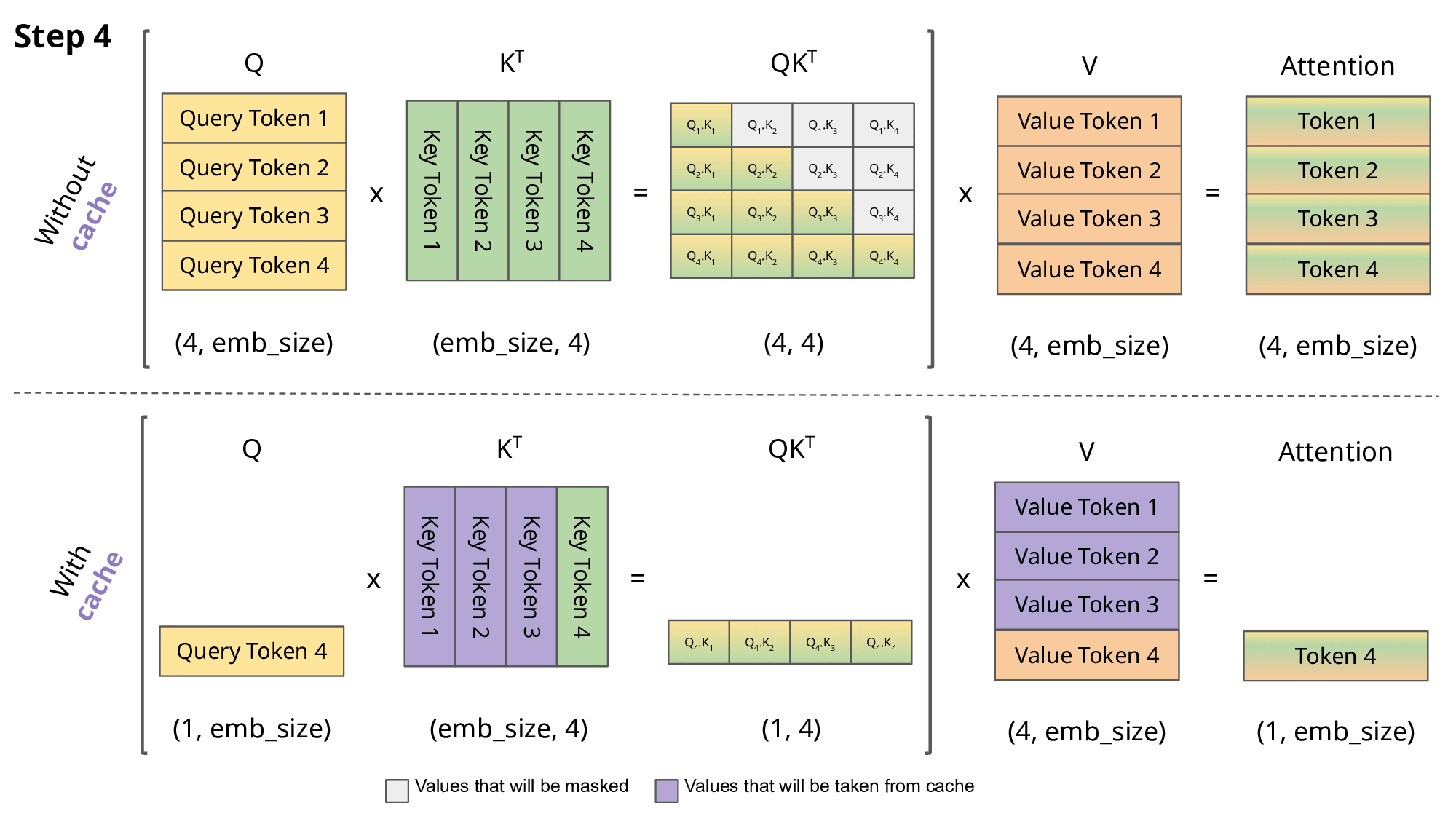
LLM 推論的困難點
那有 KV cache 就夠了嗎?vLLM 的作者群認為 KV cache 還是以下的缺點:
- 一個 model 的 KV cache 是非常大的,一個 LLaMA-13b 光是對單一序列做預測時就需要佔用 1.7GB,這樣就算有 40 GB 的 GPU 記憶體,扣除掉了 model 本身的大小,也不能做太多筆的推論; 以 13B OPT model 為例,GPU 大概會有 30% 的記憶體用來存儲 KV cache,如下圖所示:

- LLM 輸出長度難預測,所以會根據請求的最大長度(應該也就是我們常設定的 max_tokens),來分配記憶體,但這樣並沒有考慮實際輸出長度,那這樣容易造成記憶體當中的外部/內部碎片化(就是早成一些記憶體浪費)
這邊舉一個例子來說明,假如 LLM 最後生成的只有5個tokens,但你在一開始先預留了10個tokens的空間,那這樣就有多5個tokens的空間浪費掉,造成所謂的記憶體碎片化(fragmentation)的問題,浪費記憶體資源(這邊如果對 fragmentation 有興趣的話可以參考 OS 相關的書籍)
Paged Attention
再來就說到 vLLM 作者們提出的技術: Paged Attention; 他們認為如何管理 KV cache 是非常重要的技術,並參考了 OS 裡面 paging(分頁)的技術,使用 logical 與 physical 的概念,physical 才是實際記憶體儲存的地方,vLLM 允許 KV cache 存放在不連續的空間中(不用連在一起,在做 attention 的時候只要分 block 計算就好),也就是說會把 KV cache分割成多個 block (這些 block 會由 KV cache manager 管理),每個 block 中有固定數量的 KV tensor(KV block有固定大小),然後中間會有一個 paging(分頁) 來對照 logical 如何到 physical 拿資料,用這樣的方式來最大化記憶體的使用方式
以論文的圖作為例子:
- vLLM 一開始不需要為最大可能生成的序列長度保留記憶體。它只會保留在 prompt 運算過程中所生成的 KV cache 所需的 KV 區塊。例子裡面,prompt 包含 7 個 tokens(Four score and seven years ago our),因此 vLLM 將前兩個 logical KV 區塊(0 和 1)映射到兩個 physical KV 區塊(分別是 7 和 1)
- 這邊的例子是將前四個 tokens 的 KV cache 存儲在 logical 區塊 0,接下來的三個 tokens 存儲在 logical 區塊 1,然後實際會有一個 table 來對照 physical 的位置
- 在生成階段中,vLLM 使用 Paged Attention 在 physical 區塊 7 和 1 上生成新的 token。由於上一個 logical 區塊中還有一個可用的插槽,生成的 KV cache 存儲在那裡,並且 table 裡的「filled」欄位記錄會更新
- 在第二步解碼時,由於最後一個 logical 區塊已滿,vLLM 將新生成的 KV cache 存儲在一個新的 logical 區塊中;vLLM 分配了一個新的 physical 區塊(3)來存放,並將此映射記錄到 table 中

透過這樣的方式不用在一開始的時候就分配記憶體大小,而是隨者輸出動態調整。
批次操作
vLLM 也是支援 batch 操作的,推理的步驟與上面是一樣的,只是變成同時處理 2 句,應該就是每個 sequence 都會有自己的 block table,然後分別從 logical 對應到 physical上,如下圖:

其他像是 beam search、shared prompt、Parallel sampling 等方法論文也都有說明他們是怎麼操作的; 當 block 滿的時候怎麼決定哪個 block 要釋放的等一些情境論文也有提及,如果對於實作細節很介意的話,可以再去看論文。
實際操作
vLLM 有兩種方式可以推論,第一個是用它提供的 package,第二種是用 docker 的方式
使用 vLLM 的套件
$ pip install vllm- 載入 vllm package,並選擇你要inference的 model,vllm 本身是有支援 awq、gptq等一些量化方式,但不是全部量化方式都有支援,在使用前可以先去 repo 看一下支援哪些量化方法
import os
# 指定 GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from vllm import LLM, SamplingParams
import torch
llm = LLM(model='<your_model_path>', gpu_memory_utilization=0.5, max_model_len=4096, dtype=torch.half)注意:
1. 如果是用 v100 或是 T4 的 GPU 的話,dtype 要設定為 torch.half,因為不支援混和精度
2. gpu_memory_utilization 就是你希望 vLLM 幫你佔多少記憶體空間讓來儲存 KV cache
3. 不是所有的 GPU 都支援所有的量化方式(小弟之前踩過的坑QQ),像是 v100就不支援 awq 的量化方式,這邊大家需要小心
- 設定一些 generation config,相關的參數介紹可以參考這個網址,大部分與一般 LLM decode 的參數差不多
sampling_params = SamplingParams(temperature=0, max_tokens=256, top_p=1)- batch 的 function,資料 input 會像是 [”text1”, “text2”, “text3” ],然後假設我們設 n 為 2 (也就是batch為2) 那output會是 [[”text1”, “text2”], [“text3”]]
def batchify(lst: list, n: int):
return [lst[i:i + n] for i in range(0, len(lst), n)]- 開始 inference,因為在撰寫當下手邊只有工作上的一些資料,不太方便公開 QQ,這邊只提供一些程式碼
# prompt_data_list 是你的 prompt list
batchs_prompts = batchify(prompt_data_list, 10)
for batchs_idx in range(len(batchs_prompts)):
outputs = llm.generate(batchs_prompts[batchs_idx], sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(generated_text)比較
- 這一段是比較一下時間差異,我的模型都是 gptq 的模型,所以我用auto_gptq 這個套件與 vLLM 來進行比較
- 用 auto_gptq 的 code 如下:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
model_id = "<your_model_path>"
model = AutoGPTQForCausalLM.from_quantized(model_id, device_map="auto", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)
import time
start_time = time.time()
for i in range(len(prompt_data_list)):
tokenizer.decode(model.generate(**tokenizer(prompt_data_list[i], return_tensors="pt").to(model.device), max_new_tokens=256, temperature=0, pad_token_id = tokenizer.unk_token_id, eos_token_id = tokenizer.eos_token_id)[0])
end_time = time.time()
print(end_time - start_time)- 我這邊以 10 筆作實驗,vLLM 的 batch size 分別設 10 與 1,與 auto_gptq來比較一下,可以發現 vLLM 速度上真的超級快!

docker 執行
docker 這邊我就不太多介紹,基本上就是用 docker run 起來的時候設定你的模型位置等等參數
- 可以直接參考官網的連結
- 因為他本身是用 fastapi 來實作的,所以大家也可以通過在網址上輸入”http://localhost:<port>/docs”來看有哪些API來使用

- 他也支援 OpenAI 的格式,docker 相關的參數的話可以參考這邊的網址
- Inference 的參數部分與第一種方式是一樣的!
結論
vLLM 是一個蠻厲害的技術,接下來會去了解 vLLM 支援 LoRA 到什麼樣的地步,自己是比較希望 LLM 模型固定,LoRA Adapters 根據需求動態載入,這樣我只要部署一個模型就好XD,vLLM 的部分會往這方面在做研究,之後如果有一些東西想分享的會再分享在 Medium上!
參考資料
[1] vLLM Blog: https://blog.vllm.ai/2023/06/20/vllm.html
[2] vLLM 論文: Efficient Memory Management for Large Language Model Serving with PagedAttention
[3] KV cache 介紹: https://www.youtube.com/watch?v=80bIUggRJf4&ab_channel=EfficientNLP
